French language keeping pace with AI: FlauBERT, CamemBERT, PIAF
Maître PIAF tenait en son bec un camemBERT1

Nowadays, testing different NLP (Natural Language Processing) approaches is getting easier and easier: you simply need to install the appropriate libraries, download the relevant models and then analyse the data. Libraries such as scikit-learn, Transformers (both developed importantly by French contributors), spaCy, flair, to name a few, allow us to quickly test NLP models once our collection of data is ready. While this is generally true for English content, it is not the case when analysing other languages such as French: upstream tasks including sentences segmentation or tokenisation become much less of a trivial pursuit. This is mostly due to the lack of French models being (pre)-trained with quality French-language data. Unfortunately, building NLP datasets is often a time-consuming and tedious task. Plus, obtaining training datasets is not the end of the journey, given that training newer state-of-the-art algorithms may require tremendous computational resources. To address this challenge, several French-speaking research laboratories and enterprises have been working for a long time on democratizing French NLP by releasing both pre-trained models and large French-language corpora. Over the last few months, very interesting French NLP resources were developed. We are talking about CamemBERT, FlauBERT and PIAF (Pour une IA Francophone, For a French Speaking AI). The first two are pre-trained language models and the last one is a native French Question-Answering (QA) dataset. In this blogpost, we will focus on these three projects. First, we’ll briefly describe the CamemBERT and FlauBERT models. We’ll then focus on PIAF, a project we developed at Etalab. Finally, we’ll discuss how to combine these three resources to obtain the best results.
Releasing French Language Models
What/Why?
When we build a natural language processing system, we usually use machine learning. The machine only understands numbers, so we need to represent each word (or token) of our text by a list of numerical values. One of the main promises of deep learning advancements is that we do not need to explicitly determine these numerical values. In the context of NLP, this translates to having “off-the-shelf” quality representations for the words contained within our text. These representations are called “word embeddings”: vectors that represent words by means of features learned by observing large quantities of text. Furthermore, today, we can go beyond and make use of large pre-trained models that capture specificities of a given language, with the aim to address specific NLP tasks. This is what we call fine-tuning. These tasks may vary from text classification (e.g. spam or not spam), to sequential classification (whether a word is a verb or a noun or an adjective), or even more complex tasks such as question answering.
English-Onlyish
Today, NLP resources are vast and plentiful for English content. Almost every month, new models are released, promising faster and better performances. While it is true that there are multi-lingual models available, their performances are still not on par with those of specific-language pre-trained models. There is a noticeable lack of pre-trained models for French content as well as for other languages besides English.
Training is always a difficult task
One reason may be that training language-specific models is a difficult task. Firstly, we need several gigabytes of text, and secondly, we need powerful machines to run the pre-training part. The most popular language model out there, BERT, is pre-trained on over 16 Gb of data containing over 3.3 billion words. Its largest version required four full days over 64 Google TPU chips to be trained. Plus, the size of the input dataset and the amount of computational resources needed by BERT are constantly outdated by newer models. On the other hand, an exploitable advantage of these models is that once trained, they can be shared with the community and thus be used by other NLP practitioners, without requiring powerful machines and resources.
Available French BERT-like models to date
CamemBERT
The first French BERT-like language model (more precisely RoBERTa) was that of camemBERT. It was trained over OSCAR corpus, a French section of the CommonCrawl dataset (a dataset containing text of a large quantity of webpages). In the CamemBERT paper, the authors compare the performances of their French BERT-like language model against baseline models, including multi-lingual BERT-based models (mBERT and UDify) and a model that does not use contextual embeddings (UDPipe Future). To our great relief, they demonstrate the value-added of a French model when considering various NLP tasks. Their results show that, for a task we address every day here at Etalab -Named Entity Recognition (NER)-, the performance, measured by F-score, improves considerably (from 82.75 with mBERT to 87.93 with CamemBERT). NER is a fundamental step in a pseudonymisation pipeline, so this result proves that such models are very beneficial to our real-world applications.
On top of proving the added value of the French model, they show that using contextual models significantly improves results compared to a non-contextual model (UDPipe Future). This finding justifies the operational cost of contextual models, which require much more computational resources, when looking for the best performance. All in all, CamemBERT is a very useful resource for NLP practitioners working with French text. It counterbalances the mostly English-speaking NLP scene. The model is available online in the Transformers library, which makes it an actionable off-the-shelf.

FlauBERT
A few weeks after CamemBERT, FlauBERT was released. FlauBERT came also with a new French NLP evaluation benchmark (FLUE), which is useful for assessing the performance of various models. To train FlauBERT, a very similar configuration to CamemBERT (and thus BERT) is used. The details can be found in their paper. In addition, the FlauBERT team has decided to build a larger BERT version [correct?], although the training was still in process at the time of publication.
Their results show again that a French language model improves the results compared to similar BERT (multi-lingual) models as well as to other French-based models. The performances of FlauBERT and CamemBERT are very close. Unfortunately, FLUE does not include a NER benchmark in FLUE. However, in similar sequential classification tasks -constituency parsing and POS tagging-, the performance of FlauBERT is overall better than camemBERT. More interestingly, the combination FlauBERT + CamemBERT gives the best results. As the authors noted, this indicates that the two models are complementary. All in all, FlauBERT performs very similarly to CamemBERT while it is trained on fewer data. Noteworthy, FlauBERT was trained on French computing resources (the Jean Zay supercomputer of GENCI).
Building French datasets
Both camemBERT and FlauBERT models are trained on French datasets. These datasets consist in documents written in French. Indeed, a big advantage of language models is that we only need text in the targeted language to train them, and no additional treatment is required. Although, what happens when we need to address “downstream” tasks? We still need a large corpus of text to train machine learning models, and usually these require human intervention in the form of supervision such as assigning a sentiment tag, a text category, or even more complex annotations such as the generation of question-answer pairs for QA models. Although it is very time-consuming to create manually annotated datasets, this step remains essential to level up the French NLP scene with the English one.
PIAF project
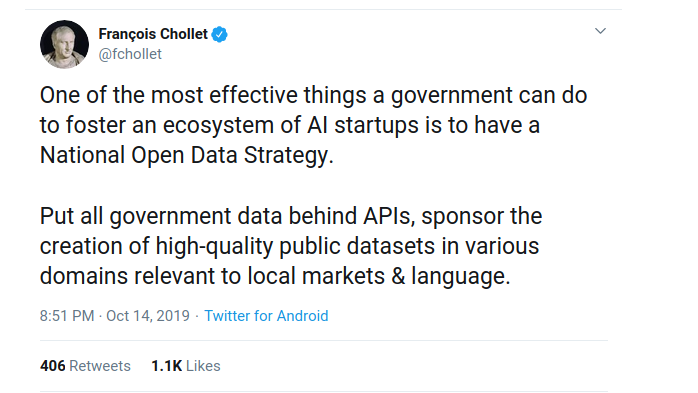
To address this issue, we are building PIAF, a native French question-answering dataset. Why did we decide to start with a Q&A dataset? One of our main objectives at Etalab is to facilitate access to information for citizens. Based on our experience of coordinating and supporting numerous data science and machine learning projects, we have witnessed how search engines play a major role in improving interactions between administrations and citizens. In order to design a new service based on a search engine, the first step is to install and maintain an Elasticsearch instance, which most of our partners (French administrations) have accomplished. Extending a search engine with a fine-grained Q&A layer could improve the general user experience by responding with more relevant and precise information. In a wider perspective, we aim to build tools and resources to facilitate French NLP and machine learning experimentation for both public and private actors. We believe this objective is shared by the community, as Francois Chollet puts it on Twitter:
Finally, as far as we know, there is no French Q&A SQuAD-like dataset, which is why we are building one in collaboration with NLP experts from the startup ReciTAL.
Our strategy
Inspired by SQuAD, the well-known English Q&A dataset, we ambition to build a similar dataset that will be openly available to all NLP practitioners. The protocol we followed is very similar to that of SQuAD v1.1. Still, some modifications had to be added to accommodate French Wikipedia’s characteristics. Another major difference is that we do not employ micro-workers through Amazon Mechanical Turk or any similar platform to create the dataset. This decision entails two key consequences: (1) we need to build a community of annotators around our project; and (2) we need an online crowd-sourcing tool to enable users to create question-answer pairs related to a set of short texts. Regarding community-building, we address the challenge by collecting annotations in two steps. In a first stage, we’ve been organizing annotation events, called annotathons, during which we provide in-house training to our potential contributors. These contributors usually come from a reduced circle within Etalab network. In the development stage, this reduced circle makes the effort manageable and enables us to collect feedback in order to modify the procedure if needed. The short training we provide helps us ensure the quality of the questions and answers, which is essential when building such a Q&A dataset. The second stage consists in opening the annotation platform to the public at large. In this stage, participants will be trained to aptly perform the Q&A task through an on-line onboarding In terms of platform, the annotation tool for Q&A we are currently developing is of course open source and can be found here. Our annotation tool aims to be as user-friendly as possible to make the task easy and interesting to our contributors.

Status
After four months of PIAF annothatons, we are proud to have now a robust annotation platform, a non-negligible amount of annotations (5000 contributions as of mid-March) and an innovative and well settled procedure for community management and collaborative participation within the French administration.
[camem|Flau]BERT + PIAF: what’s next?
What links can we make between French BERTs and PIAF? Beyond the fact that both types of resources aim to improve the French NLP R&D scene, it seems right to use one of these models (or por qué no los dos?) and fine-tune it over the Q&A task. Such experiment could be facilitated by the very useful Transformers library, developed by Hugging Face, or similar tools. For instance, NLP practitioners have already started playing with camemBERT for text pseudonymisation. For now, here at Etalab we will wait for our dataset to grow bigger and will start testing it on a few cases for our administration uses.

We still need your help!
We thank deeply our contributors who have made this project come to life until now. If you want to join the community as well and contribute to PIAF by writing Question-Answer pairs, you can do it here: piaf.etalab.studio. It will also be the opportunity to learn many interesting facts by reading Wikipedia articles! Finally, we cross our fingers to meet the community in May at the LREC conference 2020.
Update March 2020
Since the initial release of this blogpost, a few things have evolved. First, we are no longer alone in the French Q&A datasaet creation scene! Indeed, Illuin Techonology has released FQuAD, a French-native SQuAD dataset. Secondly, our PIAF paper has been accepted to LREC 2020. Unfortunately, due to the global pandemic context, the conference has been cancelled. Still, our paper will be released soon with the conference proceedings. This paper presents experiments with PIAF and FQuAD. While different, our belief is that both datasets are complementary. You can find the version of the PIAF dataset used to perform these experiments here.
-
[1] This title is a reference to the famous fable by La Fontaine Le Corbeau et le Renard, in which a crow (piaf is a colloquial word in French for bird) holds in its beak a cheese (camembert). ↩
